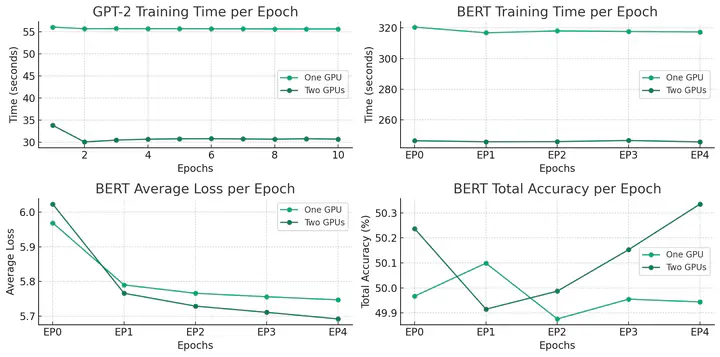
This project evaluates a custom Fully Sharded Data Parallel (FSDP) framework using PyTorch and MPI4Py for training the GPT-2 and BERT model. The aim is to compare the efficiency and effectiveness of this custom framework against PyTorch Lightning’s standard Distributed Data Parallel (DDP) and FSDP methods. We first establish a performance baseline using PyTorch Lightning’s distributed training features. Then, we develop and test a novel FSDP system with MPI4Py, focusing on managing the extensive requirements of the GPT-2 model. Performance is measured in terms of training time, GPU memory usage, throughput, and model accuracy. Success is defined by the custom framework’s ability to enhance training efficiency and scalability, compared to the baselines, while maintaining or improving model accuracy. The project aims to provide insights into the potential of custom FSDP implementations for large-scale model training.